ブレーカーを落とさないためのおうちハック
こんにちは。ぼへみあです。
突然ですが、電気のブレーカーをいきなり落とされるのって、かなり暴力的だと思いませんか?
安全上、定格電流を超えると危険なので、遮断しなければいけないのは理解できますが、
「電気を使いすぎています」という警告すら一切なく、特定の家電だけが使えなくなるのではなく
突然全電力をカットされるというのは、やりすぎだと思うのです。
昔の家電なら良くても、今の情報家電では、PCやハードディスクの書き込み中に電源を落とされると、ソフトウェア的に死ぬこともあります。
将棋のマスク反則負けでも、一度の警告すらなくすぐに反則負けにされたことが不服だと聞きましたが 電気のブレーカーも、何の警告もなしに電力全カットは、今時のシステムじゃないと思います。
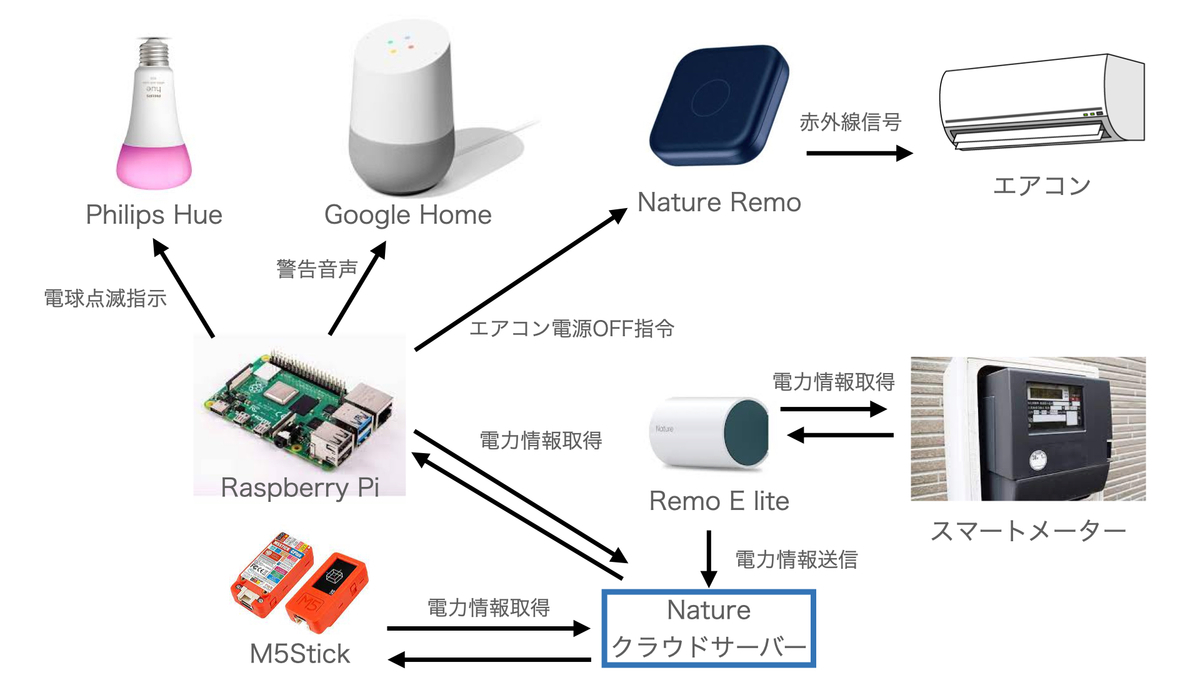
そこで今回は、ブレーカーを落とさないよう、警告してくれる&部分的に家電をOFFにするシステムを作りました。
デモの様子です。
システムの全体図です。
左右盲の人にオススメかもしれないメガネ
こんにちは。ぼへみあです。
近年、左右盲という症状が時折話題になっています。
とっさに右!と言われても、どっちが右か分からなくなる症状です。 その症状を持つ人は、幼い頃に左利きを矯正されて右利きに変わった人や、職業柄なってしまった人などがいるようです。
私自身は、あまりそういった症状はないのですが
若かりし頃、免許取り立てで後輩を乗せて車を運転していたとき、ナビに「右です」と言われたのにテンパって左に曲がってしまった事があります。
それ以降は左右盲を意識したことはありません。
メガネを新調した
話は変わるのですが、最近家族にメガネを踏まれてしまい、お気に入りのメガネが真っ二つになってしまいました。

結構気に入っていたメガネだったのでショックだったのですが
この際、もっといいメガネを買ってやろうと、メガネの聖地、鯖江まで行ってきました。
鯖江産のメガネは、国産のメガネフレームのシェアの95%を占め、メガネをしている人は鯖江に足を向けて寝られないほどです。
鯖江にはめがねミュージアムという博物館があり、メガネの歴史や製造方法を展示した施設があります。
めがねミュージアムには、福井県内約50社の最新モデルを3,000本以上展示販売しているアンテナショップが併設されています。

そこで買ったのがこのメガネ。

メガネの右側(装着したら左側)だけクリアブルーになっており、それ以外の部分は黒のメガネです。
今までに見た事がないデザインで、印象に残りやすいと思います。
背景を白にしたら分かりやすいですね。

左右盲の人に良いかも?
このメガネをかけ始めてから気づいたのですが、視界の左端だけ、青いんです。
でも普段メガネをかけていても、フレームの色はそこまで気になりません。
ちょっと意識すると、左端に青色が見える程度です。
うまく写真が撮れませんが、こんな感じで見えます

そのときふと、左右盲のことを思い出しました。
左右の判断に困ったときに、メガネフレームを見るだけで、どっちが左か分かるのではないか?
左右盲の症状がある周りの人に話を聞いてみると、左右の判断をどのように行なっているかというと、
腕時計を見る、指輪を確認する、火傷の痕を確認する、ほくろの位置を確認するなど、左右どちらかに常にあるものを確認するという、ワンステップ必要な判断をしていました。
これらの方法に比べて、メガネのフレームというのは常に視界に入っているもので、一々何かを確認するという作業が不要になります。
左右盲の人は、本当に左右がわからないのではなく、左右の判断に時間がかかることが問題なのであり、一瞬で左右が判断できるメガネフレームを使った方法は良いのではないかと思った次第です。
私自身、左右盲ではないので、本当に有効かどうかは左右盲の方に使って判断して頂かないと分かりませんが。
興味のある方は
こちらのメガネの製造は、studio skyrocketという鯖江にある眼鏡メーカーで作られています。
左右非対称のメガネを何種類か製造されています。



かっこいいポスターもありました
 studio skyrocket ブログより
studio skyrocket ブログより
取り扱いしているメガネ屋さんは全国にたくさんあるようですので、気になったという人は足を運んでみてはいかがでしょうか?
スマホを99台持って歩くとGoogleMap上で渋滞を起こせる
こんにちは。bohemiaです。
Facebookで回ってきたネタなのですが、
ベルリンのアーティストが、大量のスマホをカートに入れてゆっくり歩くと、GoogleMaps上では大量の車がゆっくり走っていると認識されて
空いている道を表す緑から、渋滞していることを示す赤色にすることができる、GoogleMapsハックができることが分かりました。
動画を見ると早いです。 www.youtube.com
このようなカートにスマホを入れて、GoogleMapsアプリを起動させた状態にしています。

その状態で道の真ん中を歩くと、GoogleMaps上で渋滞が発生し、道路が赤色になります。

結果、他の利用者のGoogleMapsでは、その道を迂回するように指示され、車がほとんどこない状態にさせることが可能とのこと。
これを行ったのは、Simon Wecketというアーティストで、ベルリンの人みたいです。 SIMON WECKERT
おそらくそれぞれのスマホにはsimカードが刺さっており、Googleアカウントも別々のものを使っていると推測されます。 このハックを利用することで、他の車には迂回させて、自分だけ空いている道を走るということも可能かな、とも思ったのですが 「ゆっくり歩いていること」GoogleMapsが渋滞であると認識する条件になっていると思いますので、できないのかな。 同じことをやって、他の車の邪魔をするだけなら可能そうです。
渋滞の認識も機械学習使ってると思うのですが、Googleが対策しようとすると、こういうスマホ大量に持ち運んでいる人のためのデータセットを作って、再学習すれば行けそうな気がします。
対策は容易なものの、バーチャル空間から現実をハックしてしまう例として、興味深いハックだと思いました。
自宅の照明をつけるだけでインターネット上を地球1周以上してた
こんにちは。ぼへみあです。
Google Homeで照明をつけたり、テレビをつけたりしているのですが、ネットワーク経由でどんなところを巡って自宅に帰ってくるのか気になって調べてみたら、地球1周以上の距離を巡っていた話です。
続きを読むスーファミ型のWifiルーターを作った
こんにちは。ぼへみあです。
去年購入したスーパーファミコンミニ、すごく手頃な大きさで、スーファミ世代には飾っても嬉しいデザインです。 この中にラズベリーパイを入れて使えたら楽しいなーと思っていたのですが、ちょうどいいケースが売っていたので 見た目はスーパーファミコンミニのWifiルーターを作りました。
まるでスーパーファミコンミニですが、中身はWifiルーターです。アクセスポイントとして機能し、Wifiに接続すればインターネットが使えます。

WifiのSSIDで隣人とコミュニケーションしよう
こんにちは。ぼへみあです。
こちらは、おうちハックアドベントカレンダーの5日目の記事になります。
スマホのテザリング機能やモバイルWifiルーターで簡単に自分の付近にWifi環境を作ることができる時代です。 ときに、このWifiのSSIDに変な名前をつけて盛り上がっている人もいます。
【これはひどい】街中で見つけた Wi-Fi名 が面白かったりひどかったりする件について - NAVER まとめ
ここで僕は、このSSIDを隣人や近くの人とのちょっとしたコミュニケーションに使えないか?と考えました。
続きを読む映画ボヘミアン・ラプソディーを観てきた
こんにちは。ぼへみあです。
普段は映画レビューなんて書かない、というか技術ブログとしてやってるので書かないようにしているのですが 今日は書いちゃいます。このブログ名で、このハンドルネームですし、Queen好きな友達も全くいないので、ここで感想を書こうと思います。
続きを読む